
假如有如下html代码需要解析
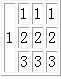
| 1 | 1 | 1 | 1 |
| 2 | 2 | 2 | |
| 3 | 3 | 3 |
我们需要以每一行为一个对象的解析过程
理想输出的结果是
1111
1222
1333
再假如有下面html
| 1 | 1 | 1 | 1 |
| 2 | 2 | 2 | |
| 3 | 3 |
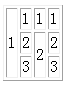
我们得到理想的结果是
1111
1222
1323
如果每次都按照这样的结果输出,就符合我们的理想, 把rowspan掉的给恢复成无rowspan的table解析起来就比较方便了
下面说解决思路, 首先我们用一个二维的String数组来表示无rowspan table的行和列
上面的我们可以声明String[][] table=new String[3][4];
表示三行四列的table
下面我开始遍历html代码的每一行,行下标用i来表示,在行的遍历代码中我们遍历每行的列,在遍历的同时我们判断这个列是不是有rowspan属性,如果有在二维数组中给i+1行的当前列(通过当前列的下标可以访问到)赋值为i行的当前单元格的值,这个rowspan被顺利读取,最后的二维数组就是我们得到的没有rowspan的table。注意在给每个单元格赋值前,需要判断当前行和当前列是不是为空的, 如果不为空则向列+1的单元格赋值 , 依此往复知道赋值成功
下面贴上我的代码,用到了jsoup(解析html利器嘛 。)
package bank.html;import java.io.File;import java.io.IOException;import java.util.ArrayList;import java.util.List;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;public class Table { private List trs; private String html; private String[][] table; private boolean isHtml; public Table(String tableHtml){ html=tableHtml; } public void parse(){ Document document=Jsoup.parse(html); Elements trsE = document.select("tr"); Elements firstTds=trsE.get(0).select("td"); table = new String[trsE.size()][firstTds.size()]; for (int row = 0; row < table.length; row++) { Element tr = trsE.get(row); Elements tds = tr.select("td"); int column = 0; for (Element td : tds) { if (td.hasAttr("rowspan")) { int rowspan = Integer.parseInt(td.attr("rowspan")); td.removeAttr("rowspan"); int endRow = rowspan + row - 1; for (int startColumn=column; endRow > row; endRow--) { boolean flag = true; int columnA=startColumn; while (flag) { if (table[endRow][columnA] == null) { table[endRow][columnA] = isHtml?td.toString():td.html(); flag=false; startColumn=columnA; } else { columnA++; } } } } boolean runing = true; do { if (table[row][column] == null) { runing = false; table[row][column] = isHtml?td.toString():td.html(); } else { runing = true; } column++; } while (runing); } } trs=new ArrayList(); for (String[] strings : table) { Tr tr=new Tr(); List tds=new ArrayList(); for (String string : strings) { Td td=new Td(); td.setContent(string); tds.add(td); } tr.setTds(tds); trs.add(tr); } } public List getTrs(){ return trs; } public String getHtml(){ return html; } public int getTrCount(){ return trs.size(); } public void isHtml(boolean v){ isHtml=v; } public static void main(String[] args) throws IOException { Document document=Jsoup.parse(new File("table.html"), "utf-8"); Elements trs=document.select("tr"); System.out.println(trs.size()); Table table=new Table(" package bank.html;import java.util.List;public class Tr { private List tds; public List getTds() { return tds; } public void setTds(List tds) { this.tds = tds; } }
package bank.html;public class Td { private String content; public String getContent() { return content; } public void setContent(String content) { this.content = content; }} 可以用上面的html代码测试,可能我描述的不够清楚,大家代码运行下就会明白的。这是我在OSC的处作,其中可能会存在问题,欢迎各路人批评指正。